Trocco's product architecture is developed to suit the practical needs of professional data engineers. Designed to take into account not only transfer speeds and connector count, but also reliability, scalability and security.
In today's data age, every business has to confront the challenge of creating meaning from the volumes and varieties of ever-growing information. Understanding what data warehousing is and distinguishing it from other types of data storage becomes important for organizations that want to leverage their data. Data warehouse and data lake are the two most important options that serve different functions and use cases. In most cases, the question is: data warehousing vs data lake- which one is appropriate for us?
This blog will delve into covering data warehousing vs data lake, exploring the definition of data warehousing and a data lake, key differences between them, business use cases, and eventually, how these concepts are evolving. The knowledge of these foundational technologies will aid you in making informed decisions while paving the way for optimization for reporting and analytics or an advanced machine learning project.
What is Data Warehousing?
A data warehouse is a centralized system built to aggregate and store structured, historical data from multiple operational sources. By contrast, transactional databases that are optimized for fast inserts and updates, data warehouses are made for heavy, read-intensive querying, analysis, and reporting. They provide a unified and consistent view of business metrics that allow stakeholders to draw insights without affecting daily business operations.
Core characteristics and components include:
Centralized repository: Consolidates ERP/CRM files, logs, spreadsheets, and external feeds into a single source of truth.
ETL/ELT pipelines: Extract, transform, and load data for the warehouse while performing quality and schema checks.
Schema design: Star or snowflake schema configuration, organizing facts (measurable events) and dimensions (contextual attributes).
Query optimization: Columnar storage, indexing, and partitioning are used to speed up complex aggregations and ad hoc queries.
A data lake is a central data repository that allows an organization to store any kind of data, be it structured, semi-structured, or unstructured, on any scale, and in its original raw format. While data warehousing demands data that is cleaned and structured before it is loaded, data lakes, however, are all about flexibility and scalability. They accept any type of data and do so without enforcing any schema.
Key characteristics of a data lake:
Schema-on-Read: In data lakes, the approach of "schema-on-read" is adopted, such that data structures are applied to data only when accessed or analyzed rather than on its storage. This allows organizations to store data in its raw form and apply structure at a later point in time, thus supporting a variety of analytics and use cases.
Variety of Data Types: Data lakes store different types of data formats, such as structured data (like tables from databases), semi-structured data (like JSON, XML), and unstructured data (like images, audio, video, and text documents).
Scalability and Cost-Effectiveness: Designed on cloud object storage or distributed file systems, data lakes can be scaled up rapidly with the increase in volumes of data in a more cost-effective way than a typical data warehouse.
Flexible Integration: They ingest data from various sources with ease—be it transactional applications, IoT devices, social media, etc.—and thus are appropriate for modern data-rich enterprises.
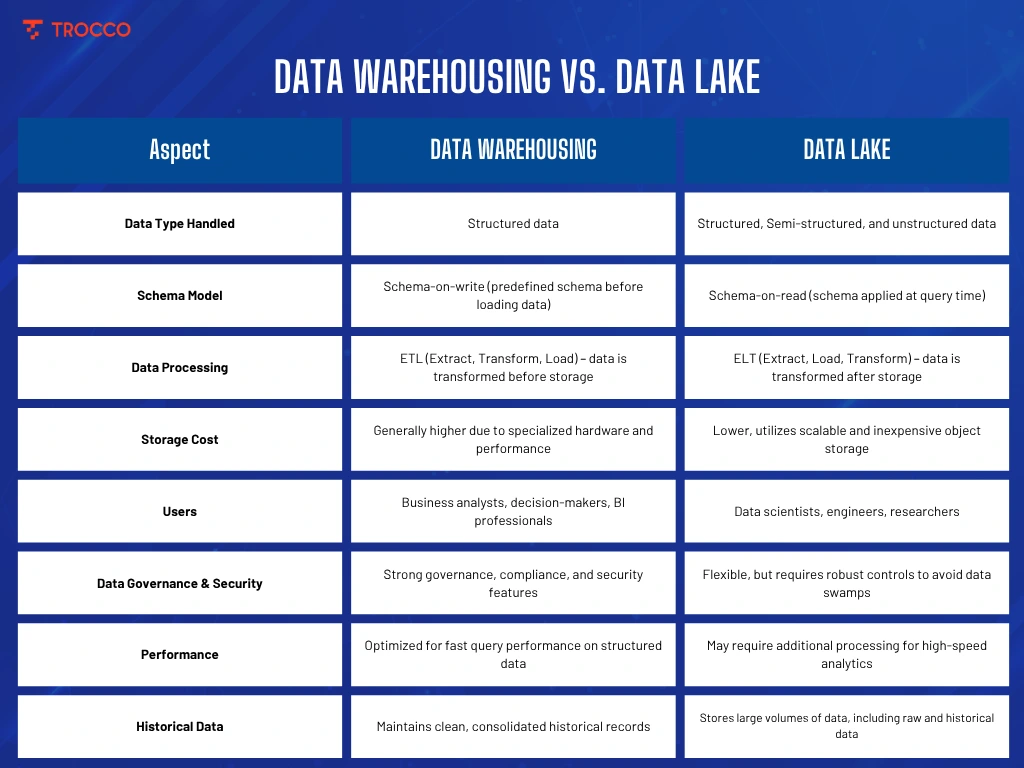
Key Differences Between Data Warehousing and Data Lakes
Data Type Handled
Data Warehouse: Mainly stores structured data that is cleaned, transformed, and organized into a defined schema. Common sources are transactional systems, CRM platforms, and ERP systems.
Data Lake: Can ingest and store structured, semi-structured, and unstructured data, including raw logs, sensor data, images, audio, and text, without enforcing a strict schema upfront.
Schema Design
Data Warehouse: Schema must be defined and enforced at the time of loading data into the warehouse. It uses a schema-on-write model. This guarantees the reliability and consistency of that data for business intelligence and reporting.
Data Lake: Using a schema-on-read model, the schema is defined and enforced at the time of data analysis. The raw data is, therefore, stored, and a flexible schema can be adopted for different analytical purposes or at the time of use in the future.
Processing and Transformation
Data Warehouse: Transformation occurs during ingestion via ETL (Extract, Transform, Load), meaning data is processed and standardized before storage.
Data Lake: Emphasizes ELT (Extract, Load, Transform), where raw data is loaded first and transformed at the point of need for analysis or application.
Cost and Scalability
Data Warehouse: The cost per storage unit tends to be on the higher side because of reliance on high-performance hardware, structured data formats, and optimized indexing.
Data Lake: Cost-efficient and scalable, with virtually unlimited capacity, through cloud object or distributed systems, a data lake would best serve as a repository for massive, heterogeneous data.
Governance, Security, and Compliance
Data Warehouse: Implements strict policies for data governance, security, and compliance, enforcing data quality, consistency, and auditability; hence, it supports regulated industries.
Data Lake: Though Data lakes can accommodate a great deal of flexibility, they raise issues concerning governance, security, and quality of data if improperly handled; hence, appropriate controls must be implemented to prevent the so-called data swamps.
Data Warehouse vs Data Lake: Structured analytics vs raw, scalable flexibility.
Explore TROCCO's Marketing Tool, which automates the integration and centralization of scattered marketing data into a single, reliable platform, enabling faster, data-driven decisions, improved ROI, and seamless collaboration across teams.
Business Use Cases: When to Choose a Data Warehouse vs a Data Lake
When to Use a Data Warehouse
Financial Reporting and Compliance: Organizations that have stringent reporting requirements, such as those in financial services, insurance, and healthcare, can benefit from a data warehouse in terms of accurate, auditable, and compliant reporting through high governance and historical records.
Sales and Marketing Analytics: Organizations seeking to gain clear insights into sales, CRM, or marketing data find the predefined schemas and historical snapshots within a data warehouse invaluable.
When to Use a Data Lake
IoT and Sensor Data Storage: Organizations engaged in data collection from connected devices or sensors, such as smart factories, logistics, or healthcare monitoring, can store unstructured and semi-structured data in data lakes for further analysis and machine learning.
Big Data Analytics and Machine Learning: Organizations focusing on large-scale analytics, experimenting with various data sources, or training AI models can take advantage of the flexibility of data lakes, where a schema is defined only upon analysis.
How Data Warehousing and Data Lakes Are Evolving
Real-Time Innovations in Data Warehouses
Cloud Native Platforms: Contemporary data warehouses can leverage cloud infrastructure for elastic scalability and high availability. Merging solutions like TROCCO with Snowflake, Google BigQuery, and Amazon Redshift enables near-instant scaling along with support for live streaming data, which makes real-time analytics much more accessible.
Streaming Data Integration: Many of the data warehouses now allow ingestion directly from some streaming platforms (for example, from Apache Kafka, AWS Kinesis), enabling the capture and analysis of live data without any delay from batch processing.
Data Lakes Embracing Real-Time Capabilities
Event-Driven Ingestion: Event streaming technologies are becoming a part of data lakes because they can push real-time data coming in from IoT devices, applications, and external feeds into the data lake.
Unified Analytical Engines: This implies that interactive and real-time analytics could be performed directly on raw data collected in the lake via engines such as Apache Spark and Databricks. They bridge the performance gap with traditional warehouses.
FAQs
What is the difference between a data lake and a data warehouse?
Data lakes are centralized repositories that can hold raw, unstructured, semi-structured, and structured data at any scale. Data lakes are based on schema-on-read, meaning the user must structure the data only when reading it for its analytical purposes. A data warehouse is the optimized storage for structured and processed data, using a fixed schema (schema-on-write), which is built for fast analytics and business intelligence tasks.
What is the difference between a data lake and a data warehouse on Google Cloud Platform (GCP)?
A GCP data lake would typically use Google Cloud Storage (GCS), which can hold vast amounts of raw data in many formats: CSVs, JSONs, images, etc. Data warehouses on GCP are implemented with solutions like BigQuery, which is an enterprise-level, fully managed, scalable serverless cloud data warehouse suitable for speedy SQL analytics on structured and semi-structured data.
What is the difference between Data Factory and Data Lake?
Data Lake: Refers to large, scalable storage for raw data in its native format, supporting diverse analytics and machine learning. Data Factory: Is not a storage system but a cloud-based ETL (extract, transform, load) data integration service (e.g., Azure Data Factory). It’s used to orchestrate data movement, transform data, and load data into destinations like data lakes or data warehouses for analytics.
Is Databricks a data lake?
Databricks is not itself a data lake; rather, it is an entire unified data analytics platform, constructed on top of a data lake architecture. The "Lakehouse" approach by Databricks is a union of all the features of a data lake with features of data management and performance of a data warehouse, allowing organizations to process, store, and analyze huge structured, semi-structured, and unstructured sets of data.
What is the difference between data space and data lake?
A data lake is a centralized repository that stores large volumes of raw, unstructured, and structured data. A data space, on the other hand, refers to a decentralized ecosystem where multiple stakeholders share and manage data under common standards and governance rules. Data lakes are typically used within an organization for analytics, machine learning, and reporting. They allow businesses to store data at scale and process it as needed. In contrast, a data space (like the European GAIA-X initiative) enables cross-organization data sharing while preserving sovereignty and compliance. Data lakes focus on storage and flexibility, while data spaces focus on collaboration, interoperability, and trust across entities.
What are examples of data warehouses?
Some popular data warehouses include Snowflake, Google BigQuery, AWS Redshift, Azure Synapse Analytics, and Oracle Autonomous Data Warehouse.
Wrapping Up
This blog delved into comparing data warehousing and data lakes, diving into both definitions, key differences between them, key business use cases, and how they are evolving. A data warehouse is appropriate if your business depends upon fast, steady reporting from structured data sources. On the other hand, a data lake is apt if you deal with huge heterogeneous datasets and demand flexibility for advanced analytics, or require real-time processing. In this new hybrid data world, a lot of organizations are therefore adding value by leveraging both options or looking at adopting a modern lake-house architecture that unifies the capabilities of both.
Ready to transform your data strategy? Start your free trial with TROCCO today to unlock the full potential of your data, driving growth and innovation.
```
Sign up for weekly updates
Get all the latest blogs delivered to your inbox
Thank you! Your submission has been received!
Oops! Something went wrong while submitting the form.







.webp)
.webp)







